Fashion MNIST Image Classification using PyTorch

![]()
![]()
![]()
![]()
![]()
Fashion-MNIST is a dataset of Zalando’s article images—consisting of a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28x28 grayscale image, associated with a label from 10 classes. Fashion-MNIST serves as a direct drop-in replacement for the original MNIST dataset for benchmarking machine learning algorithms. It shares the same image size and structure of training and testing splits.
Here’s an example how the data looks (each class takes three-rows):
![]()
Labels
Each training and test example is assigned to one of the following labels:
| Label | Description |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
Results
A validation dataset of size 12,000 was deduced from the Training dataset with its size being changed to 48,000. We train the following models for 50 epochs.
Prarameters Initialization
- Both models have been initialized with random weights sampled from a normal distribution and bias with 0.
- These parameters have been intialized only for the Linear layers present in both of the models.
- If
nrepresents number of nodes in a Linear Layer, then weights are given as a sample of normal distribution in the range(0,y). Hereyrepresents standard deviation calculated asy=1.0/sqrt(n) - Normal distribution is chosen since the probability of choosing a set of weights closer to zero in the distribution is more than that of the higher values. Unlike in Uniform distribution where probability of choosing any value is equal.
Model - 1 : FFNN
- This
Linear Modeluses 784 nodes at input layer, 512, 256 nodes in the first and second hidden layers respectively, with ouput layer of 10 nodes (10 classes). - The test accuracy is 89.56% (This result uses dropout probability of 20%)
- A
FNet_model.pthfile has been included. With this one can directly load the model state_dict and use for testing.
Model - 2 : CNN
- The
Convolutional Neural Netoworkhas 2 convolution layers and pooling layers with 3 fully connected layers. The first convolution layer takes in a channel of dimension 1 since the images are grayscaled. The kernel size is chosen to be of size 3x3 with stride of 1. The output of this convolution is set to 16 channels which means it will extract 16 feature maps using 16 kernels. We pad the image with a padding size of 1 so that the input and output dimensions are same. The output dimension at this layer will be 16 x 28 x 28. The we apply RelU activation to it followed by a max-pooling layer with kernel size of 2 and stride 2. This down-samples the feature maps to dimension of 16 x 14 x 14. - The second convolution layer will have an input channel size of 16. We choose an output channel size to be 32 which means it will extract 32 feature maps. The kernel size for this layer is 3 with stride 1. We again use a padding size of 1 so that the input and output dimension remain the same. The output dimension at this layer will be 32 x 14 x 14. We then follow up it with a RelU activation and a max-pooling layer with kernel of size 2 and stride 2. This down-samples the feature maps to dimension of 32 x 7 x 7.
- Finally, 3 fully connected layers are used. We will pass a flattened version of the feature maps to the first fully connected layer. The fully connected layers have 1568 nodes at input layer, 512, 256 nodes in the first and second hidden layers respectively, with ouput layer of 10 nodes (10 classes). So we have two fully connected layers of size 1568 x 512 followed up by 512 x 256 and 256 x 10.
- The test accuracy is 91.66% (This result uses dropout probability of 20%)
- A
convNet_model.pthfile has been included. With this one can directly load the model state_dict and use for testing.
Code: Fashion MNIST Classification
A FFNN (Feed Forward Neural Network) and CNN (Convolutional Nerual Network) have been modeled
Import required packages
import torch
from torchvision import transforms,datasets
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import SubsetRandomSampler
import matplotlib.pyplot as plt
import numpy as np
Defining our Transforms
transform=transforms.Compose([transforms.ToTensor()])
# To get the Normalization values do the follwing after downloading train data
# print(train_data.data.float().mean()/255)
# print(train_data.data.float().std()/255)
Gathering the train and test data
train_data=datasets.FashionMNIST('data',train=True,download=True,transform=transform)
test_data=datasets.FashionMNIST('data',train=False,download=True,transform=transform)
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz to data/FashionMNIST/raw/train-images-idx3-ubyte.gz
HBox(children=(FloatProgress(value=1.0, bar_style='info', max=1.0), HTML(value='')))
Extracting data/FashionMNIST/raw/train-images-idx3-ubyte.gz to data/FashionMNIST/raw
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz to data/FashionMNIST/raw/train-labels-idx1-ubyte.gz
HBox(children=(FloatProgress(value=1.0, bar_style='info', max=1.0), HTML(value='')))
Extracting data/FashionMNIST/raw/train-labels-idx1-ubyte.gz to data/FashionMNIST/raw
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz to data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz
HBox(children=(FloatProgress(value=1.0, bar_style='info', max=1.0), HTML(value='')))
Extracting data/FashionMNIST/raw/t10k-images-idx3-ubyte.gz to data/FashionMNIST/raw
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz to data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz
HBox(children=(FloatProgress(value=1.0, bar_style='info', max=1.0), HTML(value='')))
Extracting data/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz to data/FashionMNIST/raw
Processing...
Done!
/usr/local/lib/python3.6/dist-packages/torchvision/datasets/mnist.py:469: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:141.)
return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)
Defining our Train, Valid and Test Dataloaders
valid_size=0.2
train_length=len(train_data)
indices=[i for i in range(train_length)]
np.random.shuffle(indices)
split=int(np.floor(valid_size*train_length))
train_idx=indices[split:]
valid_idx=indices[:split]
train_sampler=SubsetRandomSampler(train_idx)
valid_sampler=SubsetRandomSampler(valid_idx)
num_workers=0
batch_size=20
train_loader=torch.utils.data.DataLoader(train_data,batch_size=batch_size,sampler=train_sampler,num_workers=num_workers)
valid_loader=torch.utils.data.DataLoader(train_data,batch_size=batch_size,sampler=train_sampler,num_workers=num_workers)
test_loader=torch.utils.data.DataLoader(test_data,batch_size=batch_size,num_workers=num_workers)
# This is for debugging
print(f"Training data size : {train_idx.__len__()}, Validation data size : {valid_idx.__len__()}, Test data size : {test_loader.dataset.__len__()}")
Training data size : 48000, Validation data size : 12000, Test data size : 10000
# checking our data
dataiter=iter(train_loader)
images,labels=dataiter.next()
print(images, images.shape, len(images), images[0].shape)
print()
print(labels,labels.shape,len(labels))
tensor([[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
...,
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]],
[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]]]) torch.Size([20, 1, 28, 28]) 20 torch.Size([1, 28, 28])
tensor([1, 2, 4, 1, 9, 2, 9, 7, 5, 3, 3, 3, 5, 1, 6, 6, 8, 6, 3, 2]) torch.Size([20]) 20
Visualizing a Training batch
fashion_class={
0:"T-shirt/top",
1:"Trouser",
2:"Pullover",
3:"Dress",
4:"Coat",
5:"Sandal",
6:"Shirt",
7:"Sneaker",
8:"Bag",
9:"Ankle boot"
}
fig=plt.figure(figsize=(30,10))
for i in range(len(labels)):
ax=fig.add_subplot(2,10,i+1,xticks=[],yticks=[])
plt.imshow(np.squeeze(images[i]))
ax.set_title(f"{fashion_class[labels[i].item()]}({labels[i].item()})")

Defining our Neural Net Architecture
# Model 1 : This model has dropout set to a certain value
# NOTE : When we want to use dropout we ensure we run train() method on our model --- during training , if not required we should use eval() method --- validation and testing
class FNet(nn.Module):
def __init__(self):
super(FNet,self).__init__()
self.fc1=nn.Linear(784,512)
self.fc2=nn.Linear(512,256)
self.out=nn.Linear(256,10)
# Dropout probability - set for avoiding overfitting
self.dropout=nn.Dropout(0.2)
def forward(self,x):
x = x.view(-1, 28 * 28)
x=self.dropout(F.relu(self.fc1(x)))
x=self.dropout(F.relu(self.fc2(x)))
x=self.out(x)
return x
class convNet(nn.Module):
def __init__(self):
super(convNet,self).__init__()
self.conv1=nn.Conv2d(in_channels=1,out_channels=16,kernel_size=3,padding=1,stride=1)
self.conv2=nn.Conv2d(in_channels=16,out_channels=32,kernel_size=3,padding=1,stride=1)
self.pool=nn.MaxPool2d(kernel_size=2,stride=2)
self.fc1=nn.Linear(7*7*32,512)
self.fc2=nn.Linear(512,256)
self.out=nn.Linear(256,10)
self.dropout=nn.Dropout(0.2)
def forward(self,x):
x=self.pool(F.relu(self.conv1(x)))
x=self.pool(F.relu(self.conv2(x)))
x=x.view(-1,7*7*32)
x = self.dropout(x)
x=self.dropout(F.relu(self.fc1(x)))
x=self.dropout(F.relu(self.fc2(x)))
x=self.out(x)
return x
model_1=FNet()
model_2=convNet()
def weight_init_normal(m):
classname=m.__class__.__name__
if classname.find('Linear')!=-1:
n = m.in_features
y = (1.0/np.sqrt(n))
m.weight.data.normal_(0, y)
m.bias.data.fill_(0)
model_1.apply(weight_init_normal),model_2.apply(weight_init_normal)
use_cuda=True
if use_cuda and torch.cuda.is_available():
model_1.cuda()
model_2.cuda()
print(model_1,'\n\n\n\n',model_2,'\n\n\n\n','On GPU : ',torch.cuda.is_available())
FNet(
(fc1): Linear(in_features=784, out_features=512, bias=True)
(fc2): Linear(in_features=512, out_features=256, bias=True)
(out): Linear(in_features=256, out_features=10, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
convNet(
(conv1): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=1568, out_features=512, bias=True)
(fc2): Linear(in_features=512, out_features=256, bias=True)
(out): Linear(in_features=256, out_features=10, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
On GPU : True
Defining our Loss Function
# Loss Function
# If we did not compute softmax at output use nn.CrossentropyLoss() else use nn.NLLLoss()
criterion=nn.CrossEntropyLoss()
Training and Validation Phase
def trainNet(model,lr):
optimizer=torch.optim.Adam(model.parameters(),lr=lr)
# Number of epochs to train for
loss_keeper={'train':[],'valid':[]}
epochs=50
# minimum validation loss ----- set initial minimum to infinity
valid_loss_min = np.Inf
for epoch in range(epochs):
train_loss=0.0
valid_loss=0.0
"""
TRAINING PHASE
"""
model.train() # TURN ON DROPOUT for training
for images,labels in train_loader:
if use_cuda and torch.cuda.is_available():
images,labels=images.cuda(),labels.cuda()
optimizer.zero_grad()
output=model(images)
loss=criterion(output,labels)
loss.backward()
optimizer.step()
train_loss+=loss.item()
"""
VALIDATION PHASE
"""
model.eval() # TURN OFF DROPOUT for validation
for images,labels in valid_loader:
if use_cuda and torch.cuda.is_available():
images,labels=images.cuda(),labels.cuda()
output=model(images)
loss=criterion(output,labels)
valid_loss+=loss.item()
# Calculating loss over entire batch size for every epoch
train_loss = train_loss/len(train_loader)
valid_loss = valid_loss/len(valid_loader)
# saving loss values
loss_keeper['train'].append(train_loss)
loss_keeper['valid'].append(valid_loss)
print(f"\nEpoch : {epoch+1}\tTraining Loss : {train_loss}\tValidation Loss : {valid_loss}")
if valid_loss<=valid_loss_min:
print(f"Validation loss decreased from : {valid_loss_min} ----> {valid_loss} ----> Saving Model.......")
z=type(model).__name__
torch.save(model.state_dict(), z+'_model.pth')
valid_loss_min=valid_loss
return(loss_keeper)
m1_loss=trainNet(model_1,0.001)
Epoch : 1 Training Loss : 0.5245737774328639 Validation Loss : 0.40727028745692223
Validation loss decreased from : inf ----> 0.40727028745692223 ----> Saving Model.......
Epoch : 2 Training Loss : 0.41205299500686426 Validation Loss : 0.33708525497854375
Validation loss decreased from : 0.40727028745692223 ----> 0.33708525497854375 ----> Saving Model.......
Epoch : 3 Training Loss : 0.37512027808232234 Validation Loss : 0.3269843166414648
Validation loss decreased from : 0.33708525497854375 ----> 0.3269843166414648 ----> Saving Model.......
Epoch : 4 Training Loss : 0.35627668351400643 Validation Loss : 0.2958452573659209
Validation loss decreased from : 0.3269843166414648 ----> 0.2958452573659209 ----> Saving Model.......
Epoch : 5 Training Loss : 0.3396964971123574 Validation Loss : 0.30502018353901805
Epoch : 6 Training Loss : 0.32586353985515115 Validation Loss : 0.2715637166778712
Validation loss decreased from : 0.2958452573659209 ----> 0.2715637166778712 ----> Saving Model.......
Epoch : 7 Training Loss : 0.31807561103021725 Validation Loss : 0.26199849298534295
Validation loss decreased from : 0.2715637166778712 ----> 0.26199849298534295 ----> Saving Model.......
Epoch : 8 Training Loss : 0.30708983439641696 Validation Loss : 0.26751258108221615
Epoch : 9 Training Loss : 0.30403845171366506 Validation Loss : 0.274723426499404
Epoch : 10 Training Loss : 0.29128749907889867 Validation Loss : 0.25115181813307574
Validation loss decreased from : 0.26199849298534295 ----> 0.25115181813307574 ----> Saving Model.......
Epoch : 11 Training Loss : 0.28766232713048034 Validation Loss : 0.23077004343445878
Validation loss decreased from : 0.25115181813307574 ----> 0.23077004343445878 ----> Saving Model.......
Epoch : 12 Training Loss : 0.2831367064003522 Validation Loss : 0.23832117775726752
Epoch : 13 Training Loss : 0.27554270743974485 Validation Loss : 0.23073943035308428
Validation loss decreased from : 0.23077004343445878 ----> 0.23073943035308428 ----> Saving Model.......
Epoch : 14 Training Loss : 0.2725916432214823 Validation Loss : 0.2211262550886022
Validation loss decreased from : 0.23073943035308428 ----> 0.2211262550886022 ----> Saving Model.......
Epoch : 15 Training Loss : 0.26784925135201776 Validation Loss : 0.221039225050093
Validation loss decreased from : 0.2211262550886022 ----> 0.221039225050093 ----> Saving Model.......
Epoch : 16 Training Loss : 0.26537928035346947 Validation Loss : 0.21334887140993183
Validation loss decreased from : 0.221039225050093 ----> 0.21334887140993183 ----> Saving Model.......
Epoch : 17 Training Loss : 0.259906140359235 Validation Loss : 0.22627117416278147
Epoch : 18 Training Loss : 0.25951209691023297 Validation Loss : 0.21496708430349826
Epoch : 19 Training Loss : 0.25233723516304357 Validation Loss : 0.21057498534210026
Validation loss decreased from : 0.21334887140993183 ----> 0.21057498534210026 ----> Saving Model.......
Epoch : 20 Training Loss : 0.25175181417997616 Validation Loss : 0.207845016256324
Validation loss decreased from : 0.21057498534210026 ----> 0.207845016256324 ----> Saving Model.......
Epoch : 21 Training Loss : 0.24591592026738604 Validation Loss : 0.1953360619529849
Validation loss decreased from : 0.207845016256324 ----> 0.1953360619529849 ----> Saving Model.......
Epoch : 22 Training Loss : 0.24436698967086462 Validation Loss : 0.19306999454041943
Validation loss decreased from : 0.1953360619529849 ----> 0.19306999454041943 ----> Saving Model.......
Epoch : 23 Training Loss : 0.24083079281728714 Validation Loss : 0.18058974011830287
Validation loss decreased from : 0.19306999454041943 ----> 0.18058974011830287 ----> Saving Model.......
Epoch : 24 Training Loss : 0.23969198762138452 Validation Loss : 0.19289185302419354
Epoch : 25 Training Loss : 0.23489664492231288 Validation Loss : 0.18110763866090565
Epoch : 26 Training Loss : 0.23563934576805573 Validation Loss : 0.20239229638575731
Epoch : 27 Training Loss : 0.23154691223055124 Validation Loss : 0.1905194523955773
Epoch : 28 Training Loss : 0.22806961808829024 Validation Loss : 0.18855374902564412
Epoch : 29 Training Loss : 0.22848473104221437 Validation Loss : 0.18245391538730474
Epoch : 30 Training Loss : 0.2227636545842203 Validation Loss : 0.1736720807434176
Validation loss decreased from : 0.18058974011830287 ----> 0.1736720807434176 ----> Saving Model.......
Epoch : 31 Training Loss : 0.22040115774972946 Validation Loss : 0.18376961396449285
Epoch : 32 Training Loss : 0.22619962989165893 Validation Loss : 0.17774998219176874
Epoch : 33 Training Loss : 0.22031544507665482 Validation Loss : 0.17627970401309237
Epoch : 34 Training Loss : 0.21519330151876603 Validation Loss : 0.16811999650512008
Validation loss decreased from : 0.1736720807434176 ----> 0.16811999650512008 ----> Saving Model.......
Epoch : 35 Training Loss : 0.2193748861432969 Validation Loss : 0.16050447910591173
Validation loss decreased from : 0.16811999650512008 ----> 0.16050447910591173 ----> Saving Model.......
Epoch : 36 Training Loss : 0.2162219042679741 Validation Loss : 0.16475554045309157
Epoch : 37 Training Loss : 0.21072389956447296 Validation Loss : 0.1701625347051595
Epoch : 38 Training Loss : 0.21120259532281732 Validation Loss : 0.164194766539246
Epoch : 39 Training Loss : 0.21253237069477715 Validation Loss : 0.15373909978750475
Validation loss decreased from : 0.16050447910591173 ----> 0.15373909978750475 ----> Saving Model.......
Epoch : 40 Training Loss : 0.20905702414408248 Validation Loss : 0.15264941157598513
Validation loss decreased from : 0.15373909978750475 ----> 0.15264941157598513 ----> Saving Model.......
Epoch : 41 Training Loss : 0.20989730593952116 Validation Loss : 0.1556116297193512
Epoch : 42 Training Loss : 0.1989290834204682 Validation Loss : 0.14881553952072787
Validation loss decreased from : 0.15264941157598513 ----> 0.14881553952072787 ----> Saving Model.......
Epoch : 43 Training Loss : 0.2002430260998517 Validation Loss : 0.15551074852905003
Epoch : 44 Training Loss : 0.20228995973711184 Validation Loss : 0.16045574291284234
Epoch : 45 Training Loss : 0.1990763527260909 Validation Loss : 0.15173892438089562
Epoch : 46 Training Loss : 0.19904262827740846 Validation Loss : 0.15177485206610677
Epoch : 47 Training Loss : 0.1978510423864403 Validation Loss : 0.15169739421755365
Epoch : 48 Training Loss : 0.19788050228225984 Validation Loss : 0.14420755654803846
Validation loss decreased from : 0.14881553952072787 ----> 0.14420755654803846 ----> Saving Model.......
Epoch : 49 Training Loss : 0.19404160389065508 Validation Loss : 0.13866174922861016
Validation loss decreased from : 0.14420755654803846 ----> 0.13866174922861016 ----> Saving Model.......
Epoch : 50 Training Loss : 0.1997069023375093 Validation Loss : 0.1452141469137617
m1_loss
{'train': [0.5245737774328639,
0.41205299500686426,
0.37512027808232234,
0.35627668351400643,
0.3396964971123574,
0.32586353985515115,
0.31807561103021725,
0.30708983439641696,
0.30403845171366506,
0.29128749907889867,
0.28766232713048034,
0.2831367064003522,
0.27554270743974485,
0.2725916432214823,
0.26784925135201776,
0.26537928035346947,
0.259906140359235,
0.25951209691023297,
0.25233723516304357,
0.25175181417997616,
0.24591592026738604,
0.24436698967086462,
0.24083079281728714,
0.23969198762138452,
0.23489664492231288,
0.23563934576805573,
0.23154691223055124,
0.22806961808829024,
0.22848473104221437,
0.2227636545842203,
0.22040115774972946,
0.22619962989165893,
0.22031544507665482,
0.21519330151876603,
0.2193748861432969,
0.2162219042679741,
0.21072389956447296,
0.21120259532281732,
0.21253237069477715,
0.20905702414408248,
0.20989730593952116,
0.1989290834204682,
0.2002430260998517,
0.20228995973711184,
0.1990763527260909,
0.19904262827740846,
0.1978510423864403,
0.19788050228225984,
0.19404160389065508,
0.1997069023375093],
'valid': [0.40727028745692223,
0.33708525497854375,
0.3269843166414648,
0.2958452573659209,
0.30502018353901805,
0.2715637166778712,
0.26199849298534295,
0.26751258108221615,
0.274723426499404,
0.25115181813307574,
0.23077004343445878,
0.23832117775726752,
0.23073943035308428,
0.2211262550886022,
0.221039225050093,
0.21334887140993183,
0.22627117416278147,
0.21496708430349826,
0.21057498534210026,
0.207845016256324,
0.1953360619529849,
0.19306999454041943,
0.18058974011830287,
0.19289185302419354,
0.18110763866090565,
0.20239229638575731,
0.1905194523955773,
0.18855374902564412,
0.18245391538730474,
0.1736720807434176,
0.18376961396449285,
0.17774998219176874,
0.17627970401309237,
0.16811999650512008,
0.16050447910591173,
0.16475554045309157,
0.1701625347051595,
0.164194766539246,
0.15373909978750475,
0.15264941157598513,
0.1556116297193512,
0.14881553952072787,
0.15551074852905003,
0.16045574291284234,
0.15173892438089562,
0.15177485206610677,
0.15169739421755365,
0.14420755654803846,
0.13866174922861016,
0.1452141469137617]}
m2_loss=trainNet(model_2,0.001)
Epoch : 1 Training Loss : 0.4795484571158886 Validation Loss : 0.31273220816549535
Validation loss decreased from : inf ----> 0.31273220816549535 ----> Saving Model.......
Epoch : 2 Training Loss : 0.3173350762700041 Validation Loss : 0.23918204094166867
Validation loss decreased from : 0.31273220816549535 ----> 0.23918204094166867 ----> Saving Model.......
Epoch : 3 Training Loss : 0.27447949518798853 Validation Loss : 0.2130895116176301
Validation loss decreased from : 0.23918204094166867 ----> 0.2130895116176301 ----> Saving Model.......
Epoch : 4 Training Loss : 0.24477813980154073 Validation Loss : 0.18251645672591016
Validation loss decreased from : 0.2130895116176301 ----> 0.18251645672591016 ----> Saving Model.......
Epoch : 5 Training Loss : 0.2235558565330575 Validation Loss : 0.1694691702640072
Validation loss decreased from : 0.18251645672591016 ----> 0.1694691702640072 ----> Saving Model.......
Epoch : 6 Training Loss : 0.20756078502541642 Validation Loss : 0.14767509349738248
Validation loss decreased from : 0.1694691702640072 ----> 0.14767509349738248 ----> Saving Model.......
Epoch : 7 Training Loss : 0.19212437911415084 Validation Loss : 0.13543588985155414
Validation loss decreased from : 0.14767509349738248 ----> 0.13543588985155414 ----> Saving Model.......
Epoch : 8 Training Loss : 0.18010585031496398 Validation Loss : 0.15352974321343937
Epoch : 9 Training Loss : 0.16571191259402743 Validation Loss : 0.12321102572391586
Validation loss decreased from : 0.13543588985155414 ----> 0.12321102572391586 ----> Saving Model.......
Epoch : 10 Training Loss : 0.15943761572215104 Validation Loss : 0.10332786761042372
Validation loss decreased from : 0.12321102572391586 ----> 0.10332786761042372 ----> Saving Model.......
Epoch : 11 Training Loss : 0.1476734644507936 Validation Loss : 0.09901878945368177
Validation loss decreased from : 0.10332786761042372 ----> 0.09901878945368177 ----> Saving Model.......
Epoch : 12 Training Loss : 0.13949095874687675 Validation Loss : 0.0842537117095162
Validation loss decreased from : 0.09901878945368177 ----> 0.0842537117095162 ----> Saving Model.......
Epoch : 13 Training Loss : 0.13538698722348877 Validation Loss : 0.07886038885614349
Validation loss decreased from : 0.0842537117095162 ----> 0.07886038885614349 ----> Saving Model.......
Epoch : 14 Training Loss : 0.12676684644667452 Validation Loss : 0.06918543841461845
Validation loss decreased from : 0.07886038885614349 ----> 0.06918543841461845 ----> Saving Model.......
Epoch : 15 Training Loss : 0.12330863882613509 Validation Loss : 0.07711940029228571
Epoch : 16 Training Loss : 0.11797290926730057 Validation Loss : 0.0592761817567983
Validation loss decreased from : 0.06918543841461845 ----> 0.0592761817567983 ----> Saving Model.......
Epoch : 17 Training Loss : 0.11228519654245853 Validation Loss : 0.058099494670463325
Validation loss decreased from : 0.0592761817567983 ----> 0.058099494670463325 ----> Saving Model.......
Epoch : 18 Training Loss : 0.10714266181970136 Validation Loss : 0.06826829813181878
Epoch : 19 Training Loss : 0.09973824333054533 Validation Loss : 0.04327338238050743
Validation loss decreased from : 0.058099494670463325 ----> 0.04327338238050743 ----> Saving Model.......
Epoch : 20 Training Loss : 0.10129936376109375 Validation Loss : 0.04854287591166515
Epoch : 21 Training Loss : 0.09411663640320436 Validation Loss : 0.03929548764115831
Validation loss decreased from : 0.04327338238050743 ----> 0.03929548764115831 ----> Saving Model.......
Epoch : 22 Training Loss : 0.09561268586283328 Validation Loss : 0.03389587369517737
Validation loss decreased from : 0.03929548764115831 ----> 0.03389587369517737 ----> Saving Model.......
Epoch : 23 Training Loss : 0.09034627869266236 Validation Loss : 0.03661171247569655
Epoch : 24 Training Loss : 0.08844642914188322 Validation Loss : 0.04216075532233314
Epoch : 25 Training Loss : 0.08562387986816626 Validation Loss : 0.032828559314243645
Validation loss decreased from : 0.03389587369517737 ----> 0.032828559314243645 ----> Saving Model.......
Epoch : 26 Training Loss : 0.08477398798667825 Validation Loss : 0.036523339341254464
Epoch : 27 Training Loss : 0.08143051965540432 Validation Loss : 0.026607998045423926
Validation loss decreased from : 0.032828559314243645 ----> 0.026607998045423926 ----> Saving Model.......
Epoch : 28 Training Loss : 0.08055603952888134 Validation Loss : 0.029175634944312114
Epoch : 29 Training Loss : 0.07787930377843869 Validation Loss : 0.02720605140280687
Epoch : 30 Training Loss : 0.07576567459934179 Validation Loss : 0.02299421001055085
Validation loss decreased from : 0.026607998045423926 ----> 0.02299421001055085 ----> Saving Model.......
Epoch : 31 Training Loss : 0.07473747702523004 Validation Loss : 0.02070934831689213
Validation loss decreased from : 0.02299421001055085 ----> 0.02070934831689213 ----> Saving Model.......
Epoch : 32 Training Loss : 0.07545270113245768 Validation Loss : 0.022409575816892964
Epoch : 33 Training Loss : 0.07152779797578404 Validation Loss : 0.021212398584387605
Epoch : 34 Training Loss : 0.0742624747035643 Validation Loss : 0.015471389006118634
Validation loss decreased from : 0.02070934831689213 ----> 0.015471389006118634 ----> Saving Model.......
Epoch : 35 Training Loss : 0.06874973939579182 Validation Loss : 0.020556579606571194
Epoch : 36 Training Loss : 0.07102298685327421 Validation Loss : 0.016076693334219763
Epoch : 37 Training Loss : 0.06724359062363788 Validation Loss : 0.01968076096537595
Epoch : 38 Training Loss : 0.06734503121469843 Validation Loss : 0.02031607457025866
Epoch : 39 Training Loss : 0.0640434335701202 Validation Loss : 0.014681399986749095
Validation loss decreased from : 0.015471389006118634 ----> 0.014681399986749095 ----> Saving Model.......
Epoch : 40 Training Loss : 0.0676434264319304 Validation Loss : 0.02202962383334668
Epoch : 41 Training Loss : 0.06762472466224609 Validation Loss : 0.020555324587054193
Epoch : 42 Training Loss : 0.06139595134342544 Validation Loss : 0.014432059690350746
Validation loss decreased from : 0.014681399986749095 ----> 0.014432059690350746 ----> Saving Model.......
Epoch : 43 Training Loss : 0.0659437619101114 Validation Loss : 0.014368621438416695
Validation loss decreased from : 0.014432059690350746 ----> 0.014368621438416695 ----> Saving Model.......
Epoch : 44 Training Loss : 0.06430547152827931 Validation Loss : 0.012925399918791276
Validation loss decreased from : 0.014368621438416695 ----> 0.012925399918791276 ----> Saving Model.......
Epoch : 45 Training Loss : 0.0591346730098943 Validation Loss : 0.014023829864750492
Epoch : 46 Training Loss : 0.06175600670377919 Validation Loss : 0.011199645710408188
Validation loss decreased from : 0.012925399918791276 ----> 0.011199645710408188 ----> Saving Model.......
Epoch : 47 Training Loss : 0.05995946713099471 Validation Loss : 0.013936496404054068
Epoch : 48 Training Loss : 0.057371488120178796 Validation Loss : 0.014890902989033098
Epoch : 49 Training Loss : 0.05612483223812193 Validation Loss : 0.018274710641803818
Epoch : 50 Training Loss : 0.056676250305219646 Validation Loss : 0.014393110367601783
m2_loss
{'train': [0.4795484571158886,
0.3173350762700041,
0.27447949518798853,
0.24477813980154073,
0.2235558565330575,
0.20756078502541642,
0.19212437911415084,
0.18010585031496398,
0.16571191259402743,
0.15943761572215104,
0.1476734644507936,
0.13949095874687675,
0.13538698722348877,
0.12676684644667452,
0.12330863882613509,
0.11797290926730057,
0.11228519654245853,
0.10714266181970136,
0.09973824333054533,
0.10129936376109375,
0.09411663640320436,
0.09561268586283328,
0.09034627869266236,
0.08844642914188322,
0.08562387986816626,
0.08477398798667825,
0.08143051965540432,
0.08055603952888134,
0.07787930377843869,
0.07576567459934179,
0.07473747702523004,
0.07545270113245768,
0.07152779797578404,
0.0742624747035643,
0.06874973939579182,
0.07102298685327421,
0.06724359062363788,
0.06734503121469843,
0.0640434335701202,
0.0676434264319304,
0.06762472466224609,
0.06139595134342544,
0.0659437619101114,
0.06430547152827931,
0.0591346730098943,
0.06175600670377919,
0.05995946713099471,
0.057371488120178796,
0.05612483223812193,
0.056676250305219646],
'valid': [0.31273220816549535,
0.23918204094166867,
0.2130895116176301,
0.18251645672591016,
0.1694691702640072,
0.14767509349738248,
0.13543588985155414,
0.15352974321343937,
0.12321102572391586,
0.10332786761042372,
0.09901878945368177,
0.0842537117095162,
0.07886038885614349,
0.06918543841461845,
0.07711940029228571,
0.0592761817567983,
0.058099494670463325,
0.06826829813181878,
0.04327338238050743,
0.04854287591166515,
0.03929548764115831,
0.03389587369517737,
0.03661171247569655,
0.04216075532233314,
0.032828559314243645,
0.036523339341254464,
0.026607998045423926,
0.029175634944312114,
0.02720605140280687,
0.02299421001055085,
0.02070934831689213,
0.022409575816892964,
0.021212398584387605,
0.015471389006118634,
0.020556579606571194,
0.016076693334219763,
0.01968076096537595,
0.02031607457025866,
0.014681399986749095,
0.02202962383334668,
0.020555324587054193,
0.014432059690350746,
0.014368621438416695,
0.012925399918791276,
0.014023829864750492,
0.011199645710408188,
0.013936496404054068,
0.014890902989033098,
0.018274710641803818,
0.014393110367601783]}
Loading model from Lowest Validation Loss
# Loading the model from the lowest validation loss
model_1.load_state_dict(torch.load('FNet_model.pth'))
model_2.load_state_dict(torch.load('convNet_model.pth'))
<All keys matched successfully>
print(model_1.state_dict,'\n\n\n\n',model_2.state_dict)
<bound method Module.state_dict of FNet(
(fc1): Linear(in_features=784, out_features=512, bias=True)
(fc2): Linear(in_features=512, out_features=256, bias=True)
(out): Linear(in_features=256, out_features=10, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)>
<bound method Module.state_dict of convNet(
(conv1): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=1568, out_features=512, bias=True)
(fc2): Linear(in_features=512, out_features=256, bias=True)
(out): Linear(in_features=256, out_features=10, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)>
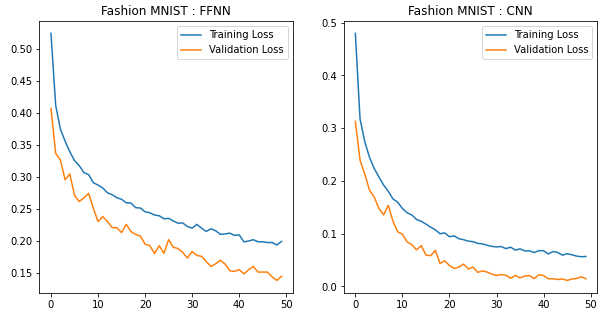
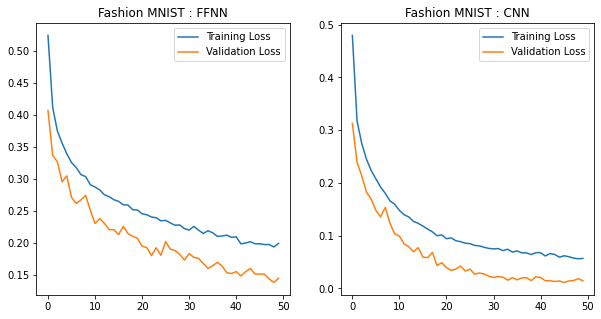
Plotting Training and Validation Losses
title=['FFNN','CNN']
model_losses=[m1_loss,m2_loss]
fig=plt.figure(1,figsize=(10,5))
idx=1
for i in model_losses:
ax=fig.add_subplot(1,2,idx)
ax.plot(i['train'],label="Training Loss")
ax.plot(i['valid'],label="Validation Loss")
ax.set_title('Fashion MNIST : '+title[idx-1])
idx+=1
plt.legend();
Testing Phase
def test(model):
correct=0
test_loss=0
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
model.eval() # test the model with dropout layers off
for images,labels in test_loader:
if use_cuda and torch.cuda.is_available():
images,labels=images.cuda(),labels.cuda()
output=model(images)
loss=criterion(output,labels)
test_loss+=loss.item()
_,pred=torch.max(output,1)
correct = np.squeeze(pred.eq(labels.data.view_as(pred)))
for i in range(batch_size):
label = labels.data[i]
class_correct[label] += correct[i].item()
class_total[label] += 1
test_loss=test_loss/len(test_loader)
print(f'For {type(model).__name__} :')
print(f"Test Loss: {test_loss}")
print(f"Correctly predicted per class : {class_correct}, Total correctly perdicted : {sum(class_correct)}")
print(f"Total Predictions per class : {class_total}, Total predictions to be made : {sum(class_total)}\n")
for i in range(10):
if class_total[i] > 0:
print(f"Test Accuracy of class {fashion_class[i]} : {float(100 * class_correct[i] / class_total[i])}% where {int(np.sum(class_correct[i]))} of {int(np.sum(class_total[i]))} were predicted correctly")
else:
print('Test Accuracy of %5s: N/A (no training examples)' % (classes[i]))
print(f"\nOverall Test Accuracy : {float(100. * np.sum(class_correct) / np.sum(class_total))}% where {int(np.sum(class_correct))} of {int(np.sum(class_total))} were predicted correctly")
# obtain one batch of test images
dataiter = iter(test_loader)
images, labels = dataiter.next()
# get sample outputs
if use_cuda and torch.cuda.is_available():
images,labels=images.cuda(),labels.cuda()
output = model(images)
# convert output probabilities to predicted class
_, preds = torch.max(output, 1)
# prep images for display
images = images.cpu().numpy()
fig = plt.figure(figsize=(15, 20))
for idx in np.arange(batch_size):
ax = fig.add_subplot(5, batch_size/5, idx+1, xticks=[], yticks=[])
plt.imshow(np.squeeze(images[idx]))
ax.set_title("{}-{} for ({}-{})".format(str(preds[idx].item()), fashion_class[preds[idx].item()],str(labels[idx].item()),fashion_class[labels[idx].item()]),
color=("blue" if preds[idx]==labels[idx] else "red"))
Visualizing a Test batch with results
FFNN
test(model_1)
For FNet :
Test Loss: 0.46673072340362703
Correctly predicted per class : [866.0, 971.0, 820.0, 932.0, 788.0, 962.0, 669.0, 974.0, 977.0, 950.0], Total correctly perdicted : 8909.0
Total Predictions per class : [1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0], Total predictions to be made : 10000.0
Test Accuracy of class T-shirt/top : 86.6% where 866 of 1000 were predicted correctly
Test Accuracy of class Trouser : 97.1% where 971 of 1000 were predicted correctly
Test Accuracy of class Pullover : 82.0% where 820 of 1000 were predicted correctly
Test Accuracy of class Dress : 93.2% where 932 of 1000 were predicted correctly
Test Accuracy of class Coat : 78.8% where 788 of 1000 were predicted correctly
Test Accuracy of class Sandal : 96.2% where 962 of 1000 were predicted correctly
Test Accuracy of class Shirt : 66.9% where 669 of 1000 were predicted correctly
Test Accuracy of class Sneaker : 97.4% where 974 of 1000 were predicted correctly
Test Accuracy of class Bag : 97.7% where 977 of 1000 were predicted correctly
Test Accuracy of class Ankle boot : 95.0% where 950 of 1000 were predicted correctly
Overall Test Accuracy : 89.09% where 8909 of 10000 were predicted correctly

CNN
test(model_2)
For convNet :
Test Loss: 0.42782994577231603
Correctly predicted per class : [861.0, 984.0, 873.0, 902.0, 878.0, 982.0, 746.0, 985.0, 985.0, 965.0], Total correctly perdicted : 9161.0
Total Predictions per class : [1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0], Total predictions to be made : 10000.0
Test Accuracy of class T-shirt/top : 86.1% where 861 of 1000 were predicted correctly
Test Accuracy of class Trouser : 98.4% where 984 of 1000 were predicted correctly
Test Accuracy of class Pullover : 87.3% where 873 of 1000 were predicted correctly
Test Accuracy of class Dress : 90.2% where 902 of 1000 were predicted correctly
Test Accuracy of class Coat : 87.8% where 878 of 1000 were predicted correctly
Test Accuracy of class Sandal : 98.2% where 982 of 1000 were predicted correctly
Test Accuracy of class Shirt : 74.6% where 746 of 1000 were predicted correctly
Test Accuracy of class Sneaker : 98.5% where 985 of 1000 were predicted correctly
Test Accuracy of class Bag : 98.5% where 985 of 1000 were predicted correctly
Test Accuracy of class Ankle boot : 96.5% where 965 of 1000 were predicted correctly
Overall Test Accuracy : 91.61% where 9161 of 10000 were predicted correctly
