CIFAR-10 Image Classification using pytorch

![]()
![]()
![]()
![]()
![]()
The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images. The dataset is divided into five training batches and one test batch, each with 10000 images. The test batch contains exactly 1000 randomly-selected images from each class. The training batches contain the remaining images in random order, but some training batches may contain more images from one class than another. Between them, the training batches contain exactly 5000 images from each class.
Here are the classes in the dataset, as well as 10 random images from each: 
Results
A validation dataset of size 10,000 was deduced from the Training dataset with its size being changed to 40,000. We train the following models for 50 epochs.
Model - 1 : FFNN
- This
Linear Modeluses 3072 nodes at input layer, 2048, 1024, 512, and 256 nodes in the first, second, third and fourth hidden layers respectively, with ouput layer of 10 nodes (10 classes). - The test accuracy is 52.81% (This result uses dropout probability of 25%)
- A
FNet_model.pthfile has been included. With this one can directly load the model state_dict and use for testing.
Model - 2 : CNN
- The
Convolutional Neural Netoworkhas 4 convolution layers and pooling layers with 2 fully connected layers. The first convolution layer takes in a channel of dimension 3 since the images are RGB. The kernel size is chosen to be of size 3x3 with stride of 1. The output of this convolution is set to 16 channels which means it will extract 16 feature maps using 16 kernels. We pad the image with a padding size of 1 so that the input and output dimensions are same. The output dimension at this layer will be 16 x 32 x 32. The we apply RelU activation to it followed by a max-pooling layer with kernel size of 2 and stride 2. This down-samples the feature maps to dimension of 16 x 16 x 16. - The second convolution layer will have an input channel size of 16. We choose an output channel size to be 32 which means it will extract 32 feature maps. The kernel size for this layer is 3 with stride 1. We again use a padding size of 1 so that the input and output dimension remain the same. The output dimension at this layer will be 32 x 16 x 16. We then follow up it with a RelU activation and a max-pooling layer with kernel of size 2 and stride 2. This down-samples the feature maps to dimension of 32 x 8 x 8.
- The third convolution layer will have an input channel size of 32. We choose an output channel size to be 64 which means it will extract 64 feature maps. The kernel size for this layer is 3 with stride 1. We again use a padding size of 1 so that the input and output dimension remain the same. The output dimension at this layer will be 64 x 8 x 8. We then follow up it with a RelU activation and a max-pooling layer with kernel of size 2 and stride 2. This down-samples the feature maps to dimension of 64 x 4 x 4.
- The fourth convolution layer will have an input channel size of 64. We choose an output channel size to be 128 which means it will extract 128 feature maps. The kernel size for this layer is 3 with stride 1. We again use a padding size of 1 so that the input and output dimension remain the same. The output dimension at this layer will be 128 x 4 x 4 followed up it with a RelU activation and a max-pooling layer with kernel of size 2 and stride 2. This down-samples the feature maps to dimension of 128 x 2 x 2.
- Finally, 3 fully connected layers are used. We will pass a flattened version of the feature maps to the first fully connected layer. The fully connected layers have 512 nodes at input layer, 256, 64 nodes in the first and second hidden layers respectively, with ouput layer of 10 nodes (10 classes). So we have two fully connected layers of size 512 x 256 followed up by 256 x 64 and 64 x 10.
- The test accuracy is 78.23% (This result uses dropout probability of 25%)
- A
convNet_model.pthfile has been included. With this one can directly load the model state_dict and use for testing.
Code: CIFAR 10
A FFNN (Feed Forward Neural Network) and CNN (Convolutional Nerual Network) have been modeled
Import required packages
import torch
from torchvision import datasets,transforms
from torch.utils.data import DataLoader, SubsetRandomSampler
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
Defining our Transforms
transform_train = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
# Normalize the test set same as training set without augmentation
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
Gathering the train and test data
train_data=datasets.CIFAR10('data',train=True,download=True,transform=transform_train)
test_data=datasets.CIFAR10('data',train=False,download=True,transform=transform_test)
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to data/cifar-10-python.tar.gz
HBox(children=(FloatProgress(value=1.0, bar_style='info', max=1.0), HTML(value='')))
Extracting data/cifar-10-python.tar.gz to data
Files already downloaded and verified
Defining our Train, Valid and Test Dataloaders
num_workers=0
batch_size=50
valid_size=0.2
train_length = len(train_data)
indices=list(range(len(train_data)))
split = int(np.floor(valid_size * train_length))
np.random.shuffle(indices)
train_idx=indices[split:]
valid_idx=indices[:split]
train_sampler=SubsetRandomSampler(train_idx)
validation_sampler=SubsetRandomSampler(valid_idx)
train_loader=DataLoader(train_data,num_workers=num_workers,batch_size=batch_size,sampler=train_sampler)
valid_loader=DataLoader(train_data,num_workers=num_workers,batch_size=batch_size,sampler=validation_sampler)
test_loader=DataLoader(test_data,shuffle=True,num_workers=num_workers,batch_size=batch_size)
dataiter=iter(train_loader)
images,labels=dataiter.next()
images,labels,images.shape,labels.shape
(tensor([[[[-1.0000, -1.0000, -0.6863, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.6941, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.6941, ..., -0.4039, -0.3490, -0.3412],
...,
[-0.7647, -0.7412, -0.6784, ..., -0.4510, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.4824, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.4902, -1.0000, -1.0000]],
[[-1.0000, -1.0000, -0.0275, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.0196, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.0353, ..., 0.0824, 0.0902, 0.1059],
...,
[-0.2706, -0.2627, -0.2784, ..., -0.2000, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.2157, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.2157, -1.0000, -1.0000]],
[[-1.0000, -1.0000, 0.1843, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, 0.2000, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, 0.1843, ..., 0.3412, 0.3725, 0.3804],
...,
[-0.3569, -0.3647, -0.3882, ..., -0.2392, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.2627, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.2627, -1.0000, -1.0000]]],
[[[-1.0000, -1.0000, -0.5529, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.2706, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.2157, ..., -0.3176, 0.3569, 0.8353],
...,
[ 0.2471, 0.2314, 0.1922, ..., 0.1137, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., 0.1529, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., 0.1922, -1.0000, -1.0000]],
[[-1.0000, -1.0000, -0.4353, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.2392, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.2235, ..., -0.2392, 0.3882, 0.8431],
...,
[ 0.2235, 0.2078, 0.1765, ..., 0.0667, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., 0.0902, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., 0.1137, -1.0000, -1.0000]],
[[-1.0000, -1.0000, -0.6078, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.3176, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.3255, ..., -0.3961, 0.2941, 0.8353],
...,
[ 0.1608, 0.1294, 0.0745, ..., -0.0275, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.0039, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., 0.0196, -1.0000, -1.0000]]],
[[[ 0.2627, -0.2157, -0.2784, ..., -0.3098, -0.3725, -0.3569],
[ 0.7882, 0.5765, 0.4275, ..., 0.0980, 0.0118, 0.0118],
[ 0.7647, 0.7647, 0.7804, ..., -0.5608, -0.4275, -0.2157],
...,
[ 0.3333, 0.1686, 0.0431, ..., -0.7882, -0.7098, -0.8275],
[ 0.2471, 0.0745, -0.0275, ..., -0.7882, -0.7176, -0.8980],
[ 0.1294, -0.0353, -0.1137, ..., -0.7098, -0.7882, -0.9608]],
[[ 0.2549, -0.1843, -0.2471, ..., -0.3098, -0.3804, -0.3647],
[ 0.7490, 0.5451, 0.3961, ..., 0.0745, -0.0353, -0.0353],
[ 0.7255, 0.7176, 0.7176, ..., -0.6078, -0.4980, -0.2941],
...,
[ 0.1922, -0.0196, -0.1529, ..., -0.8118, -0.7412, -0.8431],
[ 0.1059, -0.0902, -0.2000, ..., -0.8118, -0.7333, -0.8980],
[-0.0118, -0.1922, -0.2549, ..., -0.7412, -0.7882, -0.9529]],
[[ 0.3255, -0.0980, -0.1529, ..., -0.1922, -0.2706, -0.2549],
[ 0.7804, 0.5922, 0.4588, ..., 0.0824, -0.0196, -0.0118],
[ 0.7098, 0.7098, 0.7176, ..., -0.6157, -0.4980, -0.2706],
...,
[ 0.0510, -0.2078, -0.3725, ..., -0.7882, -0.7569, -0.8039],
[-0.0275, -0.2863, -0.4039, ..., -0.7961, -0.7569, -0.8510],
[-0.1373, -0.3725, -0.4353, ..., -0.7333, -0.7490, -0.8824]]],
...,
[[[-1.0000, -1.0000, 0.0667, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, 0.0431, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, 0.0275, ..., 0.3020, 0.2471, 0.1843],
...,
[-0.0118, 0.0118, -0.0667, ..., 0.2471, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., 0.3098, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., 0.3333, -1.0000, -1.0000]],
[[-1.0000, -1.0000, -0.0196, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.0196, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.0353, ..., 0.1059, 0.0510, -0.0039],
...,
[-0.1608, -0.1216, -0.1608, ..., 0.0980, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., 0.1451, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., 0.1765, -1.0000, -1.0000]],
[[-1.0000, -1.0000, -0.1373, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.1451, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.1608, ..., -0.1843, -0.2706, -0.3020],
...,
[-0.4588, -0.3647, -0.3412, ..., -0.1686, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.1294, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.1059, -1.0000, -1.0000]]],
[[[-1.0000, -1.0000, -0.2157, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.3176, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.3725, ..., -0.2471, -0.3020, -0.3882],
...,
[-0.0118, -0.0353, -0.0196, ..., 0.1137, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.1216, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.1373, -1.0000, -1.0000]],
[[-1.0000, -1.0000, -0.1608, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.1765, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.2078, ..., -0.1608, -0.1686, -0.1765],
...,
[ 0.0667, 0.0431, 0.0980, ..., 0.1059, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.0980, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.0980, -1.0000, -1.0000]],
[[-1.0000, -1.0000, -0.2706, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.2941, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, -1.0000, -0.3333, ..., -0.2784, -0.3255, -0.3412],
...,
[-0.1294, -0.1373, -0.1294, ..., -0.1137, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.3098, -1.0000, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.2863, -1.0000, -1.0000]]],
[[[-1.0000, 0.0824, -0.0431, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, 0.4275, 0.0980, ..., -0.2078, -0.3569, -0.1922],
[-1.0000, 0.4431, 0.4353, ..., -0.3020, -0.2549, -0.0118],
...,
[-0.2078, -0.2392, -0.1529, ..., -0.0353, 0.0275, -1.0000],
[-0.1294, -0.2314, 0.1216, ..., -0.2784, -0.2392, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.4118, -0.3176, -1.0000]],
[[-1.0000, 0.1922, 0.0588, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, 0.5451, 0.2157, ..., -0.1608, -0.2471, -0.0824],
[-1.0000, 0.5216, 0.5059, ..., -0.2078, -0.1451, 0.0980],
...,
[-0.4902, -0.5373, -0.3020, ..., 0.1843, 0.2471, -1.0000],
[-0.4275, -0.5059, -0.0353, ..., -0.0745, -0.0667, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.2314, -0.1373, -1.0000]],
[[-1.0000, -0.0510, -0.1608, ..., -1.0000, -1.0000, -1.0000],
[-1.0000, 0.2392, -0.0902, ..., -0.3255, -0.4510, -0.3255],
[-1.0000, 0.2157, 0.1922, ..., -0.3490, -0.3176, -0.1608],
...,
[-0.7020, -0.6863, -0.3569, ..., -0.2000, -0.1373, -1.0000],
[-0.6706, -0.6784, -0.1059, ..., -0.3882, -0.3647, -1.0000],
[-1.0000, -1.0000, -1.0000, ..., -0.5059, -0.4039, -1.0000]]]]),
tensor([8, 1, 3, 8, 5, 5, 0, 2, 4, 9, 9, 2, 8, 6, 1, 4, 8, 6, 5, 5, 8, 6, 6, 1,
6, 8, 3, 7, 2, 7, 8, 9, 3, 1, 8, 1, 5, 8, 1, 0, 3, 2, 4, 7, 4, 7, 3, 6,
2, 7]),
torch.Size([50, 3, 32, 32]),
torch.Size([50]))
Visualizing a Training batch
classes=['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
def RGBshow(img):
img=img*0.5+0.5
plt.imshow(np.transpose(img,(1,2,0)))
fig=plt.figure(1,figsize=(30,5))
for idx in range(batch_size):
ax=fig.add_subplot(2,batch_size/2,idx+1,xticks=[],yticks=[])
RGBshow(images[idx])
ax.set_title(classes[labels[idx]])

Defining our Neural Net Architecture
class FNet(nn.Module):
def __init__(self):
super(FNet,self).__init__()
self.fc1=nn.Linear(3*32*32,2048)
self.fc2=nn.Linear(2048,1024)
self.fc3=nn.Linear(1024,512)
self.fc4=nn.Linear(512,256)
self.out=nn.Linear(256,10)
self.dropout=nn.Dropout(0.25)
def forward(self,x):
x=x.view(-1,32*32*3)
x=self.dropout(F.relu(self.fc1(x)))
x=self.dropout(F.relu(self.fc2(x)))
x=self.dropout(F.relu(self.fc3(x)))
x=self.dropout(F.relu(self.fc4(x)))
x=self.out(x)
return x
class convNet(nn.Module):
def __init__(self):
super(convNet,self).__init__()
self.conv1=nn.Conv2d(in_channels=3,out_channels=16,kernel_size=3,stride=1,padding=1)
self.conv2=nn.Conv2d(in_channels=16,out_channels=32,kernel_size=3,stride=1,padding=1)
self.conv3=nn.Conv2d(in_channels=32,out_channels=64,kernel_size=3,stride=1,padding=1)
self.conv4=nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=1)
self.pool=nn.MaxPool2d(kernel_size=2,stride=2)
self.dropout=nn.Dropout(0.25)
self.fc1=nn.Linear(128*2*2,256)
self.fc2=nn.Linear(256,64)
self.out=nn.Linear(64,10)
def forward(self,x):
x=self.pool(F.relu(self.conv1(x)))
x=self.pool(F.relu(self.conv2(x)))
x=self.pool(F.relu(self.conv3(x)))
x=self.pool(F.relu(self.conv4(x)))
x=x.view(-1,128*2*2)
x = self.dropout(x)
x=self.dropout(F.relu(self.fc1(x)))
x=self.dropout(F.relu(self.fc2(x)))
x=self.out(x)
return x
def weight_init_normal(m):
classname=m.__class__.__name__
if classname.find('Linear')!=-1:
n = m.in_features
y = (1.0/np.sqrt(n))
m.weight.data.normal_(0, y)
m.bias.data.fill_(0)
model_1=FNet()
model_2=convNet()
model_1.apply(weight_init_normal),model_2.apply(weight_init_normal)
use_cuda=True
if use_cuda and torch.cuda.is_available():
model_1.cuda()
model_2.cuda()
print(model_1,'\n\n\n\n',model_2,'\n','On GPU : ',use_cuda and torch.cuda.is_available())
FNet(
(fc1): Linear(in_features=3072, out_features=2048, bias=True)
(fc2): Linear(in_features=2048, out_features=1024, bias=True)
(fc3): Linear(in_features=1024, out_features=512, bias=True)
(fc4): Linear(in_features=512, out_features=256, bias=True)
(out): Linear(in_features=256, out_features=10, bias=True)
(dropout): Dropout(p=0.25, inplace=False)
)
convNet(
(conv1): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv4): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(dropout): Dropout(p=0.25, inplace=False)
(fc1): Linear(in_features=512, out_features=256, bias=True)
(fc2): Linear(in_features=256, out_features=64, bias=True)
(out): Linear(in_features=64, out_features=10, bias=True)
)
On GPU : True
Defining our Loss Function
criterion=nn.CrossEntropyLoss()
Training and Validation Phase
def trainNet(model,lr,trainer,validater):
optimizer=torch.optim.Adam(model.parameters(),lr=lr)
# Number of epochs to train for
loss_keeper={'train':[],'valid':[]}
epochs=50
# minimum validation loss ----- set initial minimum to infinity
valid_loss_min = np.Inf
for epoch in range(epochs):
train_loss=0.0
valid_loss=0.0
"""
TRAINING PHASE
"""
model.train() # TURN ON DROPOUT for training
for images,labels in trainer:
if use_cuda and torch.cuda.is_available():
images,labels=images.cuda(),labels.cuda()
optimizer.zero_grad()
output=model(images)
loss=criterion(output,labels)
loss.backward()
optimizer.step()
train_loss+=loss.item()
"""
VALIDATION PHASE
"""
model.eval() # TURN OFF DROPOUT for validation
for images,labels in validater:
if use_cuda and torch.cuda.is_available():
images,labels=images.cuda(),labels.cuda()
output=model(images)
loss=criterion(output,labels)
valid_loss+=loss.item()
# Calculating loss over entire batch size for every epoch
train_loss = train_loss/len(trainer)
valid_loss = valid_loss/len(validater)
# saving loss values
loss_keeper['train'].append(train_loss)
loss_keeper['valid'].append(valid_loss)
print(f"\nEpoch : {epoch+1}\tTraining Loss : {train_loss}\tValidation Loss : {valid_loss}")
if valid_loss<=valid_loss_min:
print(f"Validation loss decreased from : {valid_loss_min} ----> {valid_loss} ----> Saving Model.......")
z=type(model).__name__
torch.save(model.state_dict(), z+'_model.pth')
valid_loss_min=valid_loss
return(loss_keeper)
m1_loss=trainNet(model_1,0.001,train_loader,valid_loader)
Epoch : 1 Training Loss : 1.8914843225479125 Validation Loss : 1.7861855268478393
Validation loss decreased from : inf ----> 1.7861855268478393 ----> Saving Model.......
Epoch : 2 Training Loss : 1.7354288077354432 Validation Loss : 1.6551058852672578
Validation loss decreased from : 1.7861855268478393 ----> 1.6551058852672578 ----> Saving Model.......
Epoch : 3 Training Loss : 1.6762275910377502 Validation Loss : 1.5982872515916824
Validation loss decreased from : 1.6551058852672578 ----> 1.5982872515916824 ----> Saving Model.......
Epoch : 4 Training Loss : 1.6390963144600392 Validation Loss : 1.569320039153099
Validation loss decreased from : 1.5982872515916824 ----> 1.569320039153099 ----> Saving Model.......
Epoch : 5 Training Loss : 1.6149707373976707 Validation Loss : 1.5382473665475844
Validation loss decreased from : 1.569320039153099 ----> 1.5382473665475844 ----> Saving Model.......
Epoch : 6 Training Loss : 1.5909801548719407 Validation Loss : 1.5273622739315034
Validation loss decreased from : 1.5382473665475844 ----> 1.5273622739315034 ----> Saving Model.......
Epoch : 7 Training Loss : 1.5719573403894902 Validation Loss : 1.5119385719299316
Validation loss decreased from : 1.5273622739315034 ----> 1.5119385719299316 ----> Saving Model.......
Epoch : 8 Training Loss : 1.5664258900284767 Validation Loss : 1.4917725038528442
Validation loss decreased from : 1.5119385719299316 ----> 1.4917725038528442 ----> Saving Model.......
Epoch : 9 Training Loss : 1.5479162077605724 Validation Loss : 1.4794976264238358
Validation loss decreased from : 1.4917725038528442 ----> 1.4794976264238358 ----> Saving Model.......
Epoch : 10 Training Loss : 1.5298011289536952 Validation Loss : 1.4838168799877167
Epoch : 11 Training Loss : 1.5173952253162861 Validation Loss : 1.4592884463071822
Validation loss decreased from : 1.4794976264238358 ----> 1.4592884463071822 ----> Saving Model.......
Epoch : 12 Training Loss : 1.5045500868558883 Validation Loss : 1.4744983237981797
Epoch : 13 Training Loss : 1.4998823773860932 Validation Loss : 1.4237676686048508
Validation loss decreased from : 1.4592884463071822 ----> 1.4237676686048508 ----> Saving Model.......
Epoch : 14 Training Loss : 1.4900255347788334 Validation Loss : 1.4450950422883033
Epoch : 15 Training Loss : 1.4883685764670371 Validation Loss : 1.4622361773252488
Epoch : 16 Training Loss : 1.4720067113637925 Validation Loss : 1.4289284247159957
Epoch : 17 Training Loss : 1.4649032546579839 Validation Loss : 1.4292354905605316
Epoch : 18 Training Loss : 1.45382926620543 Validation Loss : 1.4154022270441056
Validation loss decreased from : 1.4237676686048508 ----> 1.4154022270441056 ----> Saving Model.......
Epoch : 19 Training Loss : 1.4481224296987056 Validation Loss : 1.4194352132081987
Epoch : 20 Training Loss : 1.443694968894124 Validation Loss : 1.4206243014335633
Epoch : 21 Training Loss : 1.4364663189649582 Validation Loss : 1.414353666305542
Validation loss decreased from : 1.4154022270441056 ----> 1.414353666305542 ----> Saving Model.......
Epoch : 22 Training Loss : 1.4286708252131939 Validation Loss : 1.4074067002534867
Validation loss decreased from : 1.414353666305542 ----> 1.4074067002534867 ----> Saving Model.......
Epoch : 23 Training Loss : 1.4269703105092049 Validation Loss : 1.4086483860015868
Epoch : 24 Training Loss : 1.4123086772859097 Validation Loss : 1.4008913445472717
Validation loss decreased from : 1.4074067002534867 ----> 1.4008913445472717 ----> Saving Model.......
Epoch : 25 Training Loss : 1.4123282507807016 Validation Loss : 1.4060809576511384
Epoch : 26 Training Loss : 1.4244192230701447 Validation Loss : 1.3919382655620576
Validation loss decreased from : 1.4008913445472717 ----> 1.3919382655620576 ----> Saving Model.......
Epoch : 27 Training Loss : 1.4051923021674155 Validation Loss : 1.4121574145555496
Epoch : 28 Training Loss : 1.3934523110091686 Validation Loss : 1.414674077630043
Epoch : 29 Training Loss : 1.3902008696645498 Validation Loss : 1.4055598932504654
Epoch : 30 Training Loss : 1.3938843380659818 Validation Loss : 1.4222955483198165
Epoch : 31 Training Loss : 1.3826227422058581 Validation Loss : 1.4005932646989823
Epoch : 32 Training Loss : 1.3815101287513971 Validation Loss : 1.3832740697264672
Validation loss decreased from : 1.3919382655620576 ----> 1.3832740697264672 ----> Saving Model.......
Epoch : 33 Training Loss : 1.374132251739502 Validation Loss : 1.3827075296640396
Validation loss decreased from : 1.3832740697264672 ----> 1.3827075296640396 ----> Saving Model.......
Epoch : 34 Training Loss : 1.3610564179718494 Validation Loss : 1.3699653512239456
Validation loss decreased from : 1.3827075296640396 ----> 1.3699653512239456 ----> Saving Model.......
Epoch : 35 Training Loss : 1.36209069930017 Validation Loss : 1.386518095433712
Epoch : 36 Training Loss : 1.3622202119231224 Validation Loss : 1.3919783371686936
Epoch : 37 Training Loss : 1.3631627985835075 Validation Loss : 1.3732400453090667
Epoch : 38 Training Loss : 1.3622260969877242 Validation Loss : 1.3735718673467636
Epoch : 39 Training Loss : 1.3544758398085832 Validation Loss : 1.3697906437516212
Validation loss decreased from : 1.3699653512239456 ----> 1.3697906437516212 ----> Saving Model.......
Epoch : 40 Training Loss : 1.3410094776004553 Validation Loss : 1.3697432869672774
Validation loss decreased from : 1.3697906437516212 ----> 1.3697432869672774 ----> Saving Model.......
Epoch : 41 Training Loss : 1.337626836448908 Validation Loss : 1.362401696741581
Validation loss decreased from : 1.3697432869672774 ----> 1.362401696741581 ----> Saving Model.......
Epoch : 42 Training Loss : 1.3394730857014656 Validation Loss : 1.3455607271194459
Validation loss decreased from : 1.362401696741581 ----> 1.3455607271194459 ----> Saving Model.......
Epoch : 43 Training Loss : 1.322536734715104 Validation Loss : 1.3449425733089446
Validation loss decreased from : 1.3455607271194459 ----> 1.3449425733089446 ----> Saving Model.......
Epoch : 44 Training Loss : 1.3242478519678116 Validation Loss : 1.3568071007728577
Epoch : 45 Training Loss : 1.3359934682399035 Validation Loss : 1.3915830782055856
Epoch : 46 Training Loss : 1.3374974434822797 Validation Loss : 1.3609652507305146
Epoch : 47 Training Loss : 1.3279900383204222 Validation Loss : 1.3523581320047378
Epoch : 48 Training Loss : 1.3266761530190707 Validation Loss : 1.368416508436203
Epoch : 49 Training Loss : 1.3257682911306619 Validation Loss : 1.3743300771713256
Epoch : 50 Training Loss : 1.3056953228265047 Validation Loss : 1.359510282278061
m1_loss
{'train': [1.8914843225479125,
1.7354288077354432,
1.6762275910377502,
1.6390963144600392,
1.6149707373976707,
1.5909801548719407,
1.5719573403894902,
1.5664258900284767,
1.5479162077605724,
1.5298011289536952,
1.5173952253162861,
1.5045500868558883,
1.4998823773860932,
1.4900255347788334,
1.4883685764670371,
1.4720067113637925,
1.4649032546579839,
1.45382926620543,
1.4481224296987056,
1.443694968894124,
1.4364663189649582,
1.4286708252131939,
1.4269703105092049,
1.4123086772859097,
1.4123282507807016,
1.4244192230701447,
1.4051923021674155,
1.3934523110091686,
1.3902008696645498,
1.3938843380659818,
1.3826227422058581,
1.3815101287513971,
1.374132251739502,
1.3610564179718494,
1.36209069930017,
1.3622202119231224,
1.3631627985835075,
1.3622260969877242,
1.3544758398085832,
1.3410094776004553,
1.337626836448908,
1.3394730857014656,
1.322536734715104,
1.3242478519678116,
1.3359934682399035,
1.3374974434822797,
1.3279900383204222,
1.3266761530190707,
1.3257682911306619,
1.3056953228265047],
'valid': [1.7861855268478393,
1.6551058852672578,
1.5982872515916824,
1.569320039153099,
1.5382473665475844,
1.5273622739315034,
1.5119385719299316,
1.4917725038528442,
1.4794976264238358,
1.4838168799877167,
1.4592884463071822,
1.4744983237981797,
1.4237676686048508,
1.4450950422883033,
1.4622361773252488,
1.4289284247159957,
1.4292354905605316,
1.4154022270441056,
1.4194352132081987,
1.4206243014335633,
1.414353666305542,
1.4074067002534867,
1.4086483860015868,
1.4008913445472717,
1.4060809576511384,
1.3919382655620576,
1.4121574145555496,
1.414674077630043,
1.4055598932504654,
1.4222955483198165,
1.4005932646989823,
1.3832740697264672,
1.3827075296640396,
1.3699653512239456,
1.386518095433712,
1.3919783371686936,
1.3732400453090667,
1.3735718673467636,
1.3697906437516212,
1.3697432869672774,
1.362401696741581,
1.3455607271194459,
1.3449425733089446,
1.3568071007728577,
1.3915830782055856,
1.3609652507305146,
1.3523581320047378,
1.368416508436203,
1.3743300771713256,
1.359510282278061]}
m2_loss=trainNet(model_2,0.001,train_loader,valid_loader)
Epoch : 1 Training Loss : 1.716832646280527 Validation Loss : 1.372470233440399
Validation loss decreased from : inf ----> 1.372470233440399 ----> Saving Model.......
Epoch : 2 Training Loss : 1.338187035098672 Validation Loss : 1.1747579601407052
Validation loss decreased from : 1.372470233440399 ----> 1.1747579601407052 ----> Saving Model.......
Epoch : 3 Training Loss : 1.1763792869448662 Validation Loss : 1.0562058836221695
Validation loss decreased from : 1.1747579601407052 ----> 1.0562058836221695 ----> Saving Model.......
Epoch : 4 Training Loss : 1.0854558511078358 Validation Loss : 1.0284024575352668
Validation loss decreased from : 1.0562058836221695 ----> 1.0284024575352668 ----> Saving Model.......
Epoch : 5 Training Loss : 1.0104725854843855 Validation Loss : 0.9176352521777154
Validation loss decreased from : 1.0284024575352668 ----> 0.9176352521777154 ----> Saving Model.......
Epoch : 6 Training Loss : 0.9721706546097993 Validation Loss : 0.9357278496026993
Epoch : 7 Training Loss : 0.9350394625216722 Validation Loss : 0.8809126132726669
Validation loss decreased from : 0.9176352521777154 ----> 0.8809126132726669 ----> Saving Model.......
Epoch : 8 Training Loss : 0.8908793176710605 Validation Loss : 0.8489409692585468
Validation loss decreased from : 0.8809126132726669 ----> 0.8489409692585468 ----> Saving Model.......
Epoch : 9 Training Loss : 0.8700262823328376 Validation Loss : 0.8517181207239628
Epoch : 10 Training Loss : 0.849644378721714 Validation Loss : 0.8097402659058571
Validation loss decreased from : 0.8489409692585468 ----> 0.8097402659058571 ----> Saving Model.......
Epoch : 11 Training Loss : 0.8214490864053369 Validation Loss : 0.8070604813098907
Validation loss decreased from : 0.8097402659058571 ----> 0.8070604813098907 ----> Saving Model.......
Epoch : 12 Training Loss : 0.8020877300575375 Validation Loss : 0.8069178926944732
Validation loss decreased from : 0.8070604813098907 ----> 0.8069178926944732 ----> Saving Model.......
Epoch : 13 Training Loss : 0.7864096334949136 Validation Loss : 0.801924984306097
Validation loss decreased from : 0.8069178926944732 ----> 0.801924984306097 ----> Saving Model.......
Epoch : 14 Training Loss : 0.772134379260242 Validation Loss : 0.7835563471913338
Validation loss decreased from : 0.801924984306097 ----> 0.7835563471913338 ----> Saving Model.......
Epoch : 15 Training Loss : 0.7597009083256125 Validation Loss : 0.7942057918012142
Epoch : 16 Training Loss : 0.749008767567575 Validation Loss : 0.7465972143411637
Validation loss decreased from : 0.7835563471913338 ----> 0.7465972143411637 ----> Saving Model.......
Epoch : 17 Training Loss : 0.7426711942255497 Validation Loss : 0.7659854030609131
Epoch : 18 Training Loss : 0.7281675378233194 Validation Loss : 0.7388511615991592
Validation loss decreased from : 0.7465972143411637 ----> 0.7388511615991592 ----> Saving Model.......
Epoch : 19 Training Loss : 0.7243577725812793 Validation Loss : 0.7433983883261681
Epoch : 20 Training Loss : 0.7076545771956444 Validation Loss : 0.787526145875454
Epoch : 21 Training Loss : 0.7071526535600424 Validation Loss : 0.7476475384831428
Epoch : 22 Training Loss : 0.7023186306655407 Validation Loss : 0.7551596134901046
Epoch : 23 Training Loss : 0.6896255945786833 Validation Loss : 0.7224876855313778
Validation loss decreased from : 0.7388511615991592 ----> 0.7224876855313778 ----> Saving Model.......
Epoch : 24 Training Loss : 0.6929806116595865 Validation Loss : 0.7371938496828079
Epoch : 25 Training Loss : 0.6732358633354306 Validation Loss : 0.7593043768405914
Epoch : 26 Training Loss : 0.6808948734775185 Validation Loss : 0.700516471862793
Validation loss decreased from : 0.7224876855313778 ----> 0.700516471862793 ----> Saving Model.......
Epoch : 27 Training Loss : 0.6677980388328433 Validation Loss : 0.7325647233426571
Epoch : 28 Training Loss : 0.6625024812668562 Validation Loss : 0.7031043569743634
Epoch : 29 Training Loss : 0.6534148543328047 Validation Loss : 0.725356979817152
Epoch : 30 Training Loss : 0.6557108856737613 Validation Loss : 0.6878647838532924
Validation loss decreased from : 0.700516471862793 ----> 0.6878647838532924 ----> Saving Model.......
Epoch : 31 Training Loss : 0.641195742227137 Validation Loss : 0.72365159034729
Epoch : 32 Training Loss : 0.6362130276672542 Validation Loss : 0.7064743733406067
Epoch : 33 Training Loss : 0.6313847859948873 Validation Loss : 0.7099564972519875
Epoch : 34 Training Loss : 0.6336773931607604 Validation Loss : 0.7052300693094731
Epoch : 35 Training Loss : 0.6285666101053358 Validation Loss : 0.7257260385155678
Epoch : 36 Training Loss : 0.622393993139267 Validation Loss : 0.6890241387486458
Epoch : 37 Training Loss : 0.6228110155463219 Validation Loss : 0.7075248755514622
Epoch : 38 Training Loss : 0.6265616923198104 Validation Loss : 0.6890628705918789
Epoch : 39 Training Loss : 0.6128259899094701 Validation Loss : 0.7373508244752884
Epoch : 40 Training Loss : 0.6157739811018109 Validation Loss : 0.7100131288170815
Epoch : 41 Training Loss : 0.6117634375020862 Validation Loss : 0.693013071268797
Epoch : 42 Training Loss : 0.6048382629826665 Validation Loss : 0.7173259402811527
Epoch : 43 Training Loss : 0.6052186808735133 Validation Loss : 0.6957827849686146
Epoch : 44 Training Loss : 0.5989311215840281 Validation Loss : 0.6695359195768833
Validation loss decreased from : 0.6878647838532924 ----> 0.6695359195768833 ----> Saving Model.......
Epoch : 45 Training Loss : 0.5986734641715884 Validation Loss : 0.6939946077764034
Epoch : 46 Training Loss : 0.5926671144552529 Validation Loss : 0.6884895312786102
Epoch : 47 Training Loss : 0.6029079894721509 Validation Loss : 0.7003341059386731
Epoch : 48 Training Loss : 0.5862549842521548 Validation Loss : 0.6850902111828328
Epoch : 49 Training Loss : 0.5863980263471603 Validation Loss : 0.6839123617112637
Epoch : 50 Training Loss : 0.5868628399260342 Validation Loss : 0.6905731400847435
m2_loss
{'train': [1.716832646280527,
1.338187035098672,
1.1763792869448662,
1.0854558511078358,
1.0104725854843855,
0.9721706546097993,
0.9350394625216722,
0.8908793176710605,
0.8700262823328376,
0.849644378721714,
0.8214490864053369,
0.8020877300575375,
0.7864096334949136,
0.772134379260242,
0.7597009083256125,
0.749008767567575,
0.7426711942255497,
0.7281675378233194,
0.7243577725812793,
0.7076545771956444,
0.7071526535600424,
0.7023186306655407,
0.6896255945786833,
0.6929806116595865,
0.6732358633354306,
0.6808948734775185,
0.6677980388328433,
0.6625024812668562,
0.6534148543328047,
0.6557108856737613,
0.641195742227137,
0.6362130276672542,
0.6313847859948873,
0.6336773931607604,
0.6285666101053358,
0.622393993139267,
0.6228110155463219,
0.6265616923198104,
0.6128259899094701,
0.6157739811018109,
0.6117634375020862,
0.6048382629826665,
0.6052186808735133,
0.5989311215840281,
0.5986734641715884,
0.5926671144552529,
0.6029079894721509,
0.5862549842521548,
0.5863980263471603,
0.5868628399260342],
'valid': [1.372470233440399,
1.1747579601407052,
1.0562058836221695,
1.0284024575352668,
0.9176352521777154,
0.9357278496026993,
0.8809126132726669,
0.8489409692585468,
0.8517181207239628,
0.8097402659058571,
0.8070604813098907,
0.8069178926944732,
0.801924984306097,
0.7835563471913338,
0.7942057918012142,
0.7465972143411637,
0.7659854030609131,
0.7388511615991592,
0.7433983883261681,
0.787526145875454,
0.7476475384831428,
0.7551596134901046,
0.7224876855313778,
0.7371938496828079,
0.7593043768405914,
0.700516471862793,
0.7325647233426571,
0.7031043569743634,
0.725356979817152,
0.6878647838532924,
0.72365159034729,
0.7064743733406067,
0.7099564972519875,
0.7052300693094731,
0.7257260385155678,
0.6890241387486458,
0.7075248755514622,
0.6890628705918789,
0.7373508244752884,
0.7100131288170815,
0.693013071268797,
0.7173259402811527,
0.6957827849686146,
0.6695359195768833,
0.6939946077764034,
0.6884895312786102,
0.7003341059386731,
0.6850902111828328,
0.6839123617112637,
0.6905731400847435]}
Loading model from Lowest Validation Loss
# Loading the model from the lowest validation loss
model_1.load_state_dict(torch.load('FNet_model.pth'))
model_2.load_state_dict(torch.load('convNet_model.pth'))
<All keys matched successfully>
print(model_1.state_dict,'\n\n\n\n',model_2.state_dict)
<bound method Module.state_dict of FNet(
(fc1): Linear(in_features=3072, out_features=2048, bias=True)
(fc2): Linear(in_features=2048, out_features=1024, bias=True)
(fc3): Linear(in_features=1024, out_features=512, bias=True)
(fc4): Linear(in_features=512, out_features=256, bias=True)
(out): Linear(in_features=256, out_features=10, bias=True)
(dropout): Dropout(p=0.25, inplace=False)
)>
<bound method Module.state_dict of convNet(
(conv1): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv4): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(dropout): Dropout(p=0.25, inplace=False)
(fc1): Linear(in_features=512, out_features=256, bias=True)
(fc2): Linear(in_features=256, out_features=64, bias=True)
(out): Linear(in_features=64, out_features=10, bias=True)
)>
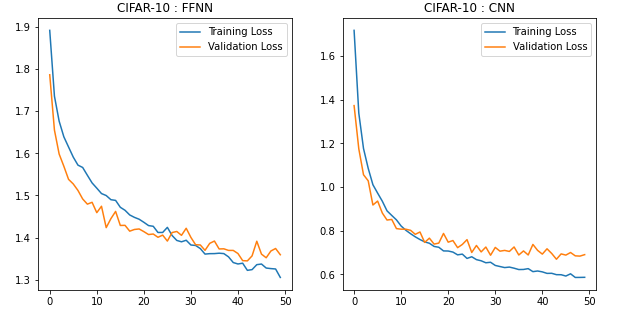
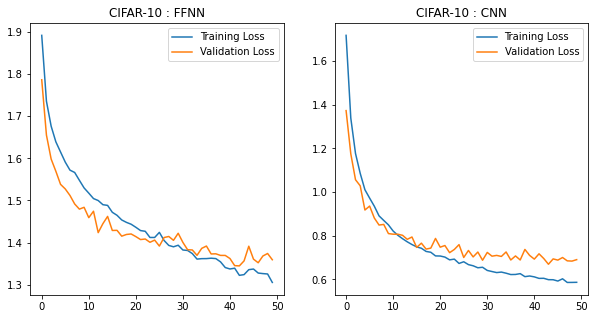
Plotting Training and Validation Losses
title=['FFNN','CNN']
model_losses=[m1_loss,m2_loss]
fig=plt.figure(1,figsize=(10,5))
idx=1
for i in model_losses:
ax=fig.add_subplot(1,2,idx)
ax.plot(i['train'],label="Training Loss")
ax.plot(i['valid'],label="Validation Loss")
ax.set_title('CIFAR-10 : '+title[idx-1])
idx+=1
plt.legend();
Testing Phase
def test(model):
test_loss=0
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
model.eval() # test the model with dropout layers off
for images,labels in test_loader:
if use_cuda and torch.cuda.is_available():
images,labels=images.cuda(),labels.cuda()
output=model(images)
loss=criterion(output,labels)
test_loss+=loss.item()
_,pred=torch.max(output,1)
correct = np.squeeze(pred.eq(labels.data.view_as(pred)))
for idx in range(batch_size):
label = labels[idx]
class_correct[label] += correct[idx].item()
class_total[label] += 1
test_loss=test_loss/len(test_loader)
print(f'For {type(model).__name__} :')
print(f"Test Loss: {test_loss}")
print(f"Correctly predicted per class : {class_correct}, Total correctly perdicted : {sum(class_correct)}")
print(f"Total Predictions per class : {class_total}, Total predictions to be made : {sum(class_total)}\n")
for i in range(10):
if class_total[i] > 0:
print(f"Test Accuracy of class {classes[i]} : {float(100 * class_correct[i] / class_total[i])}% where {int(np.sum(class_correct[i]))} of {int(np.sum(class_total[i]))} were predicted correctly")
else:
print('Test Accuracy of %5s: N/A (no training examples)' % (classes[i]))
print(f"\nOverall Test Accuracy : {float(100. * np.sum(class_correct) / np.sum(class_total))}% where {int(np.sum(class_correct))} of {int(np.sum(class_total))} were predicted correctly")
# obtain one batch of test images
dataiter = iter(test_loader)
images, labels = dataiter.next()
# get sample outputs
if use_cuda and torch.cuda.is_available():
images,labels=images.cuda(),labels.cuda()
output = model(images)
# convert output probabilities to predicted class
_, preds = torch.max(output, 1)
# prep images for display
images = images.cpu().numpy()
# plot the images in the batch, along with predicted and true labels
fig = plt.figure(figsize=(25, 15))
for idx in np.arange(batch_size):
ax = fig.add_subplot(5, batch_size/5, idx+1, xticks=[], yticks=[])
RGBshow(np.squeeze(images[idx]))
ax.set_title("{}({}) for {}({})".format(classes[preds[idx]],str(preds[idx].item()), classes[labels[idx]],str(labels[idx].item())),
color=("blue" if preds[idx]==labels[idx] else "red"))
Visualizing a Test batch with results
FFNN
test(model_1)
For FNet :
Test Loss: 1.3889298540353776
Correctly predicted per class : [606.0, 710.0, 339.0, 361.0, 504.0, 368.0, 579.0, 568.0, 717.0, 529.0], Total correctly perdicted : 5281.0
Total Predictions per class : [1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0], Total predictions to be made : 10000.0
Test Accuracy of class airplane : 60.6% where 606 of 1000 were predicted correctly
Test Accuracy of class automobile : 71.0% where 710 of 1000 were predicted correctly
Test Accuracy of class bird : 33.9% where 339 of 1000 were predicted correctly
Test Accuracy of class cat : 36.1% where 361 of 1000 were predicted correctly
Test Accuracy of class deer : 50.4% where 504 of 1000 were predicted correctly
Test Accuracy of class dog : 36.8% where 368 of 1000 were predicted correctly
Test Accuracy of class frog : 57.9% where 579 of 1000 were predicted correctly
Test Accuracy of class horse : 56.8% where 568 of 1000 were predicted correctly
Test Accuracy of class ship : 71.7% where 717 of 1000 were predicted correctly
Test Accuracy of class truck : 52.9% where 529 of 1000 were predicted correctly
Overall Test Accuracy : 52.81% where 5281 of 10000 were predicted correctly

CNN
test(model_2)
For convNet :
Test Loss: 0.6464765165746212
Correctly predicted per class : [823.0, 892.0, 683.0, 575.0, 769.0, 636.0, 851.0, 853.0, 864.0, 877.0], Total correctly perdicted : 7823.0
Total Predictions per class : [1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0], Total predictions to be made : 10000.0
Test Accuracy of class airplane : 82.3% where 823 of 1000 were predicted correctly
Test Accuracy of class automobile : 89.2% where 892 of 1000 were predicted correctly
Test Accuracy of class bird : 68.3% where 683 of 1000 were predicted correctly
Test Accuracy of class cat : 57.5% where 575 of 1000 were predicted correctly
Test Accuracy of class deer : 76.9% where 769 of 1000 were predicted correctly
Test Accuracy of class dog : 63.6% where 636 of 1000 were predicted correctly
Test Accuracy of class frog : 85.1% where 851 of 1000 were predicted correctly
Test Accuracy of class horse : 85.3% where 853 of 1000 were predicted correctly
Test Accuracy of class ship : 86.4% where 864 of 1000 were predicted correctly
Test Accuracy of class truck : 87.7% where 877 of 1000 were predicted correctly
Overall Test Accuracy : 78.23% where 7823 of 10000 were predicted correctly
