5. Bias-Variance
"Avoid the mistake of overfitting and underfitting."
As a machine learning practitioner, it is important to have a good understanding of how to build effective models with high accuracy. A common pitfall in training a model is overfitting and underfitting. Let us look at these topics so the next time you build a model, you would exactly know how to avoid the mistake of overfitting and underfitting.
Bias-Variance Trade-off
"The two variables to measure the effectiveness of your model are bias and variance."
Bias is the error or difference between points given and points plotted on the line in your training set.
Variance is the error that occurs due to sensitivity to small changes in the training set.
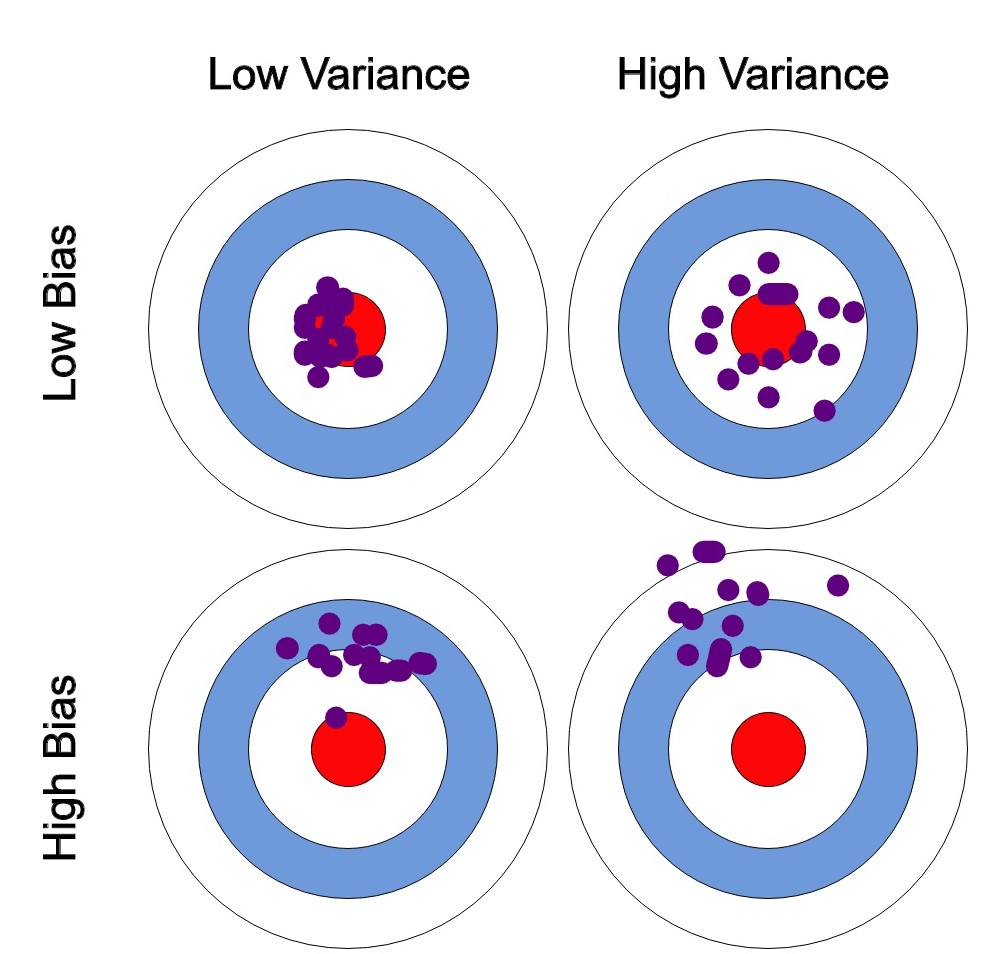
-
I’ll be explaining bias-variance further with the help of the image above. So please follow along.
-
To simply things, let us say, the error is calculated as the difference between predicted and observed/actual value. Now, say we have a model that is very accurate. This means that the error is very less, indicating a low bias and low variance. (As seen on the top-left circle in the image).
-
If the variance increases, the data is spread more which results in lower accuracy. (As seen on the top-right circle in the image).
-
If the bias increases, the error calculated increases. (As seen on the bottom-left circle in the image).
-
High variance and high bias indicate that data is spread with a high error. (As seen on the bottom-right circle in the image).
-
This is Bias-Variance Tradeoff. Earlier, I defined bias as a measure of error between what the model captures and what the available data is showing, and variance being the error from sensitivity to small changes in the available data. A model having high variance captures random noise in the data.
-
We want to find the best fit line that has low bias and low variance. (As seen on the top-left circle in the image).
How do parameters affect our model?
-
Model complexity keeps increasing as the number of parameters increase. This could result in overfitting, basically increasing variance and decreasing bias.
-
Our aim is to come up with a point in our model where the decrease in bias is equal to an increase in variance. So how do we do this? Let us look at model fitting.
Model Fitting
- We can find a line that represents the general direction of the points but might not represent every point in the dataset. This would be the best fit model.
Why not use higher-order polynomials always?
-
Good question. Sadly, the answer is no. By doing so, we would have created a model that fits our training data very well but fails to generalize beyond the training set (say any testing data that the model was not trained on). Therefore our model performs poorly on the test data giving rise to less accuracy. This problem is called over-fitting. We also say that the model has high variance and low bias.
-
Similarly, we have another issue. It is called underfitting. It occurs when our model neither fits the training data nor generalizes on the new data (say any testing data that the model was not trained on). Our model is underfitting when we have high bias and low variance.
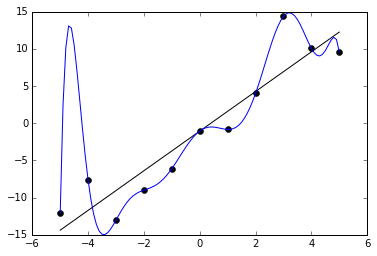
The image above shows a blue line which is a polynomial regression line. The straight black line is that of a linear function. Although the polynomial function is a perfect fit, the linear function can be expected to generalize better. Thus, we can say that the polynomial function is overfitting, on the other hand, the straight line is the best fit. Think of an imaginary line that hardly passes through any of those points. That would be underfitting.
How to overcome Underfitting & Overfitting for a regression model?
-
To overcome underfitting or high bias, we can add new parameters to our model so that the model complexity increases thus reducing high bias.
-
To overcome overfitting, we could use methods like reducing model complexity and regularization.